Developing complex software systems for large enterprises in a truly agile way presents us with challenges on many levels: cultural, organizational, financial, infrastructural and architectural. In our blog post series, we look at various problems of scaled agility from a holistic company perspective and try to give practical suggestions for improvement.
Data and its intelligent use have always been the basis of decision and knowledge management.
With increasing digitization, data competence has long since become a question of competitive advantage and survival, even for modern agile companies.
One might think that agility and data competence are mutually dependent and mutually supportive. In practice, however, this is not always the case. In other words, there is still room for improvement. Let’s go into some details!
Data, Facts, Humans
Data and its intelligent use are no new inventions. With increasing digitization and the wide availability of AI and Big Data technologies, data literacy has become as important for each of us as reading and writing. And for companies, data literacy has become one of the most crucial factor regarding competition and survival.
If it were that easy! Already in 2009, Erik Brynjolfsson, an economist and director of the Massachusetts Institute of Technology’s Center for Digital Business, stated: “We’re rapidly entering a world where everything can be monitored and measured. But the big problem is going to be the ability of humans to use, analyse and make sense of the data”.[1]
As with optical illusions, we seem to be easily fooled by data, as well. We don’t recognize fake news and artificially generated photos or videos overwhelm us even more. Elections are rigged and before we can unmask the nefarious machinations, the wrong person is already in power. Software solutions such as chatgpt generate scientific papers and blog articles, but without marking the text as “AI-generated” and without citing sources. At second glance and with a little practice, the quality is fortunately (still) far too bad, otherwise this article might have been generated by a machine, as well.
In his book “Factfulness” (2018), Hans Rosling describes a completely different kind of data incompetence, which could perhaps be described as sociological-medial biased. Rosling provides numerous examples of how we ignore or misinterpret statistics on the basis of our very own “instincts” and, thus, time and again are mercilessly wrong when it comes to global political issues, such as poverty, education, population growth and much more.[2]
What does that tell us? We can use big data and AI for data analysis, for decision recommendations, predictions or for text and image generation; In the end, however, what counts are the ethical values and creativity of humans. And what does that mean for companies? How can agile companies in particular use data competence with all its facets and integrate it into their culture and processes? What challenges exist from the point of view of leadership, organization and professional as well as technical competence?
Data Literacy in a Nutshell
Before we turn to data literacy in agile companies, we would like to spend a few sentences on our own definition. Data literacy connects the data to be collected and the problem to be solved. In the end, it is about gaining information from data that is relevant for decisions and actions. Data literacy encompasses both technical skills, such as the use of data analysis tools, and the ability to critically evaluate data from an ethical and other perspectives in a larger context.
In essence, it is irrelevant whether intelligent algorithms and tools are involved in the automated processing of large (unstructured) amounts of data or not. Applying AI to data and hoping that structured knowledge will emerge is simply illusory.
Data processing must be planned, the search space restricted, the right parameters defined, the right questions formulated, a suitable model found or even newly developed. Aspects regarding ethics, sustainability and compliance as well as questions about the quality of data and sources do come into play here. Later, data must be checked, classified, and interpreted in context. Last but not least, there is the skilled application: a decision, a classification, a recommendation for action or even an automatic, machine-generated action. Finally, the use case is expanded, other aspects and more data are to be included: the game starts again.
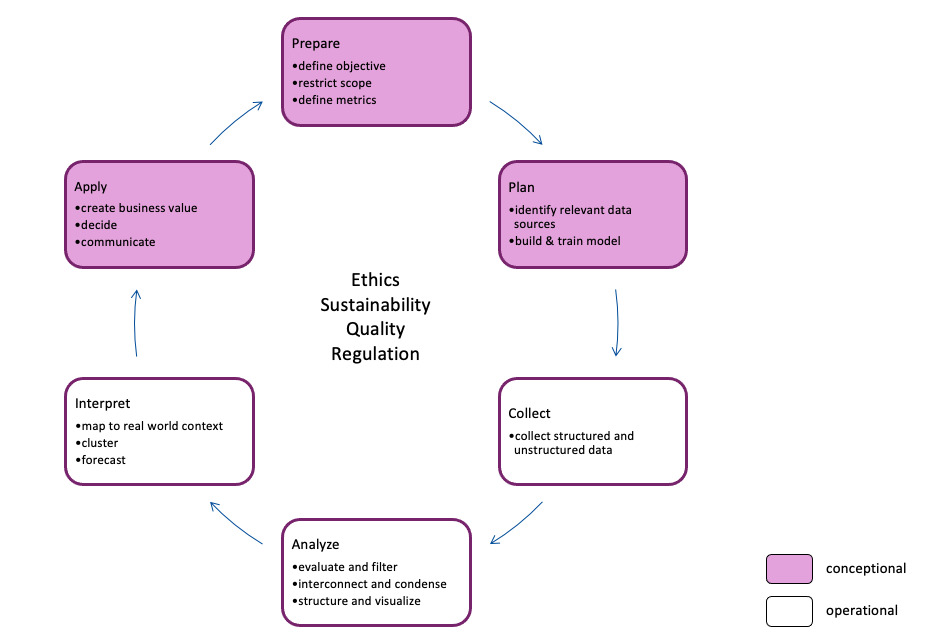
We have therefore based our definition of data literacy on the AISNSW cycle model [3] (see figure; we will come back to the meaning of the colouring later). We understand data competency (data literacy) as the ability to make fact-based decisions for an enterprise on the basis of data. In addition to methodological and technical knowledge, this requires careful preparation and the critical and creative handling of data in its respective context. With competency comes the responsibility to formulate requirements for ethics, sustainability, quality and regulation for the entire data cycle. The data literacy charter [4] of the “Stifterverband” poses the following questions: What do I want / can I / am I allowed to / should I do with data?
Data literate and agile – the perfect Match
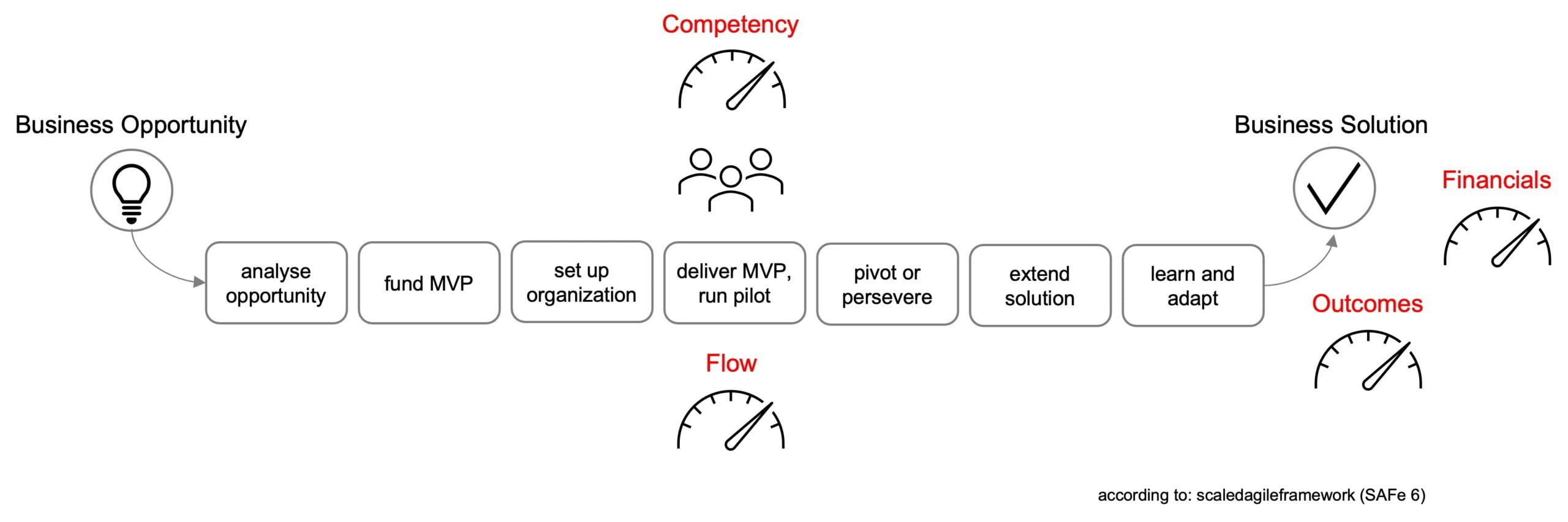
Basically, agility and data competence have a high degree of mutual affinity. Agile values such as transparency, cooperation and measurability (“measure and grow”) place high demands on data quality and assessment competency. The agile framework SAFe® distinguishes three categories of key figures: Flow to measure efficiency, Competency as a measure of organizational maturity and Outcome to evaluate strategic goals and the actual benefits delivered (see figure)[5]. The OKRs (Objectives and Key Results) described by us in the last article belong to the third category. We added a fourth category to the standard financial KPIs: Financials.
With the advent of big data and AI, the demands for data literacy, but also the opportunities for companies, have increased dramatically. We can classify their importance for scaled-agile product development into three use cases:
- Automate processes:
Data-based and AI-supported applications can deal with complex scenarios and many parameters and can be used for advanced automation up to complex decision-making systems, intelligent assistance solutions and autonomous controls.
For example, this can lead to a better understanding of customer needs, a largely automated assessment of damage reports, conducting customer dialogues with intelligent chatbots, the creation of tailor-made service offers for customers, the detection of fraud attempts in the financial sector, the transport of people and goods through autonomous vehicles, etc. The list of smart applications is endless and will continue to dramatically transform the way we live.
- Support strategic decisions:
If strategic goals are formulated in a measurable way, subjective, delayed, manual decisions can be further developed into data-driven and AI-supported decisions. The quality of the data is improved (more measuring points) and the speed of decision-making is increased (being up to date, availability and processing speed).
For example, customer satisfaction can be determined automatically via an automated evaluation of facial expressions instead of manually, via feedback forms or the approval of a political candidate. Even the complex evaluation of a perfume fragrance can be determined in this way.[6]
Further, the formulation of parameters themselves could be solved by AI one day in the not too distant future. First attempts of the automated definition of OKRs can be found on the website of an OKR generator.[7]
- Evaluate business models:
Business models can be expanded, optimized or secured in a variety of ways using big data and AI. Customer needs and opportunities or risks from market changes can be identified more precisely and earlier. In complex multi-scenario simulations, digital twins can provide valuable information about their originals in the physical world. Autonomous transport systems or medical micro-robots in our bloodstream are pathing the way for completely new business areas.
Anchoring Data Literacy in the Enterprise
As we have seen, the requirements for data competence, big data and AI are extremely complex and affect all areas of a company. And one thing is also clear: either a company develops this competency, or it will not be able to survive. What also matters, is the right mix between data expertise and technological competence, but also between expert knowledge and a generalist mindset. In order to be able to anchor data competence into an enterprise long term, i.e., also into the corporate culture, measures are required on four levels:
- Technical infrastructure
Both company-wide cloud infrastructures and domain-specific, e.g. portfolio-wide, data lakes with high-quality data are the basic requirement for data- and AI-driven software.
- Professional and technical competence
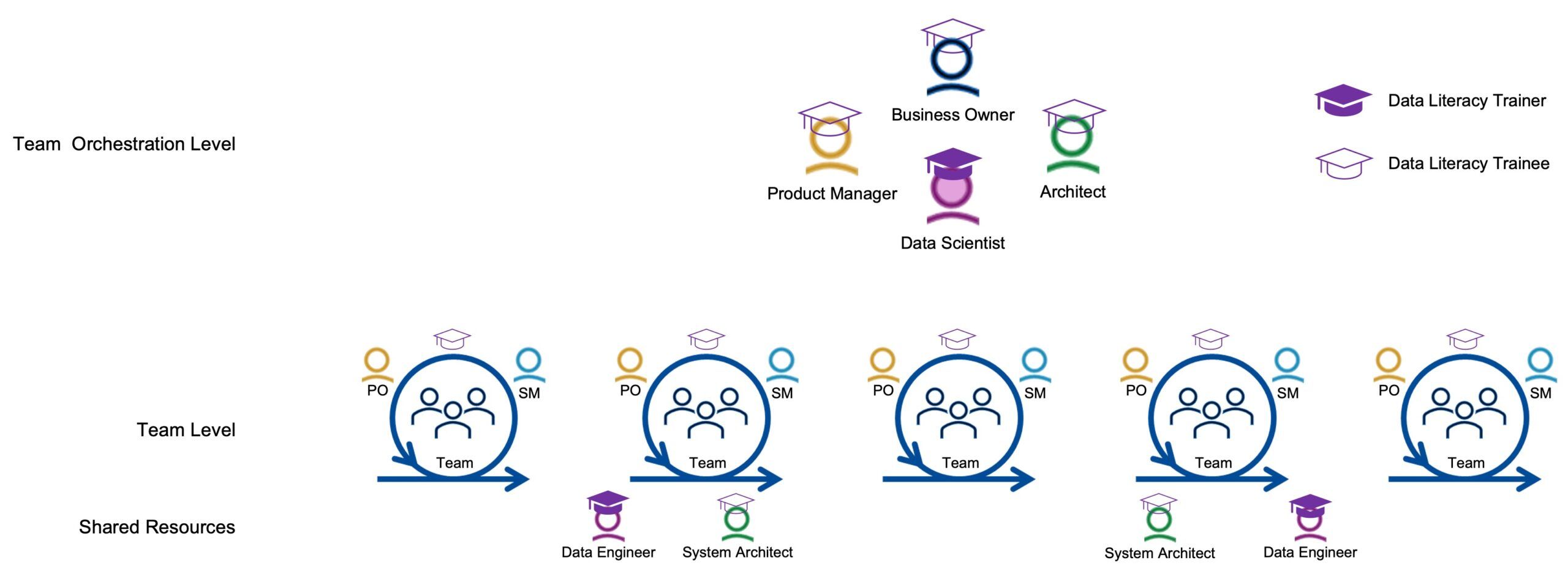
We propose the use of the existing roles “Data Scientist” and “Data Engineer” in order to give a home to the technical-conceptual-business-oriented (purple activities in the data literacy cycle) on the one hand and the architectural-implementation-technical-operative (white activities) competence focuses on the other.
In addition, the competence of many other existing agile roles is required to integrate data, model, AI algorithms and tools into new and existing value streams, into the design methods, into the DevOps pipeline and into the IT infrastructure.
- Organization
From an organizational point of view, data scientists have an overarching scope and ensure that data and models are defined and functional and utilizable for the entire company or portfolio, while data engineers focus more on empowering the implementation teams (see figure “Organizational model”). We also suggest that both roles conduct specific training for complementary roles at their levels.
A second essential organizational aspect of data competence in agile companies is the provision and maintenance of a dashboard for the above-mentioned agile business agility metrics that can be viewed by everyone. Instead of classic reporting lines, such a dashboard creates extensive transparency and empowerment to everyone in real time.
- Leadership
People in leadership roles should have a good understanding of the opportunities and risks of Big Data beyond their own context. They must be able to correctly evaluate business models, define strategic goals and make them measurable, correctly assess budget requirements for data-driven applications or AI models from product management and weigh them against business opportunities. They need to recognize the importance of investing in infrastructure, human resources and training, and promoting general awareness of data literacy through example and proactive measures. Particularly important in an agile context: they must be willing to actively involve roles with data competence in the decision-making and implementation processes.
Key Take-Aways
Data literacy has already become a critical factor for the competitiveness of companies. The widespread availability of Big Data and AI accelerates this development dramatically. The competent handling of data supports the quality and the efficiency of decision-making and new business models, but also helps to avert danger.
Due to the compatibility of business agility and data competence, agile companies can integrate the competent handling of data very well into their processes, structures and technical infrastructures.
The prerequisite is a data-savvy leadership culture that actively promotes data competence at all levels of the company.
Data scientists and data engineers take on other key functions. On the one hand, as data experts, they take on the data competence trainings and, on the other hand, support existing agile roles at various levels with the operational handling of data-based or AI-based applications.
With the set of measures described in the areas of “technical infrastructure”, “professional and technical competence”, “organization” and “leadership”, an agile company can efficiently and sustainably anchor data competence as a core competence in its own DNA.
___
[1] For Today’s Graduate, Just One Word: Statistics – The New York Times (nytimes.com), https://www.nytimes.com/2009/08/06/technology/06stats.html
[2] His daughter-in-law Anna Rosling-Rönnlund gives an entertaining insight into this world of data and its incorrect interpretation in a Tedd Talk:
https://www.youtube.com/watch?v=u4L130DkdOw
[3] Association of Independent Schools in New South Wales, Australia, https://www.aisnsw.edu.au/, Link to Document
[4] Katharina Schüller, Henning Koch, Florian Rampelt: Data Literacy Charter, 2021, https://www.stifterverband.org/sites/default/files/data-literacy-charter.pdf
[5] More on: https://scaledagileframework.com/measure-and-grow/
[6] See also: https://www.linkedin.com/pulse/how-can-managers-use-ai-freshen-up-measurement-sam-ransbotham




